Here's what I'll do: portions = [0.1]*10 cv = df7.randomSplit (portions) folds = list (range (10)) for i in range (10): test_data = cv [i] fold_no_i = folds [:i] + folds [i+1:] train_data = cv [fold_no_i [0]] for j in fold_no_i [1:]: train_data = train_data.union (cv [j]) ngoc thoag Jun 26, 2019 at 20:03 To run the Hello World example (or any PySpark program) with the running Docker container, first access the shell as described above. I have changed your code a bit but this is basically how you can run parallel tasks, The code below shows how to perform parallelized (and distributed) hyperparameter tuning when using scikit-learn. So, you must use one of the previous methods to use PySpark in the Docker container.  As with filter() and map(), reduce()applies a function to elements in an iterable. Possible ESD damage on UART pins between nRF52840 and ATmega1284P, Split a CSV file based on second column value. I want to do parallel processing in for loop using pyspark. ). Spark uses Resilient Distributed Datasets (RDD) to perform parallel processing across a cluster or computer processors.
As with filter() and map(), reduce()applies a function to elements in an iterable. Possible ESD damage on UART pins between nRF52840 and ATmega1284P, Split a CSV file based on second column value. I want to do parallel processing in for loop using pyspark. ). Spark uses Resilient Distributed Datasets (RDD) to perform parallel processing across a cluster or computer processors.  How to add a new column to an existing DataFrame? This is recognized as the MapReduce framework because the division of labor can usually be characterized by sets of the map, shuffle, and reduce operations found in functional programming. The snippet below shows how to instantiate and train a linear regression model and calculate the correlation coefficient for the estimated house prices. Create SparkConf object : val conf = new SparkConf ().setMaster ("local").setAppName ("testApp") How can a Wizard procure rare inks in Curse of Strahd or otherwise make use of a looted spellbook?
How to add a new column to an existing DataFrame? This is recognized as the MapReduce framework because the division of labor can usually be characterized by sets of the map, shuffle, and reduce operations found in functional programming. The snippet below shows how to instantiate and train a linear regression model and calculate the correlation coefficient for the estimated house prices. Create SparkConf object : val conf = new SparkConf ().setMaster ("local").setAppName ("testApp") How can a Wizard procure rare inks in Curse of Strahd or otherwise make use of a looted spellbook?  The full notebook for the examples presented in this tutorial are available on GitHub and a rendering of the notebook is available here. Is renormalization different to just ignoring infinite expressions? There are higher-level functions that take care of forcing an evaluation of the RDD values. Not the answer you're looking for? Newbie question: As iterating an already collected dataframe "beats the purpose", from a dataframe, how should I pick the rows I need for further processing? Azure Databricks: Python parallel for loop. Not the answer you're looking for? Asking for help, clarification, or responding to other answers. Webhow to vacuum car ac system without pump.
The full notebook for the examples presented in this tutorial are available on GitHub and a rendering of the notebook is available here. Is renormalization different to just ignoring infinite expressions? There are higher-level functions that take care of forcing an evaluation of the RDD values. Not the answer you're looking for? Newbie question: As iterating an already collected dataframe "beats the purpose", from a dataframe, how should I pick the rows I need for further processing? Azure Databricks: Python parallel for loop. Not the answer you're looking for? Asking for help, clarification, or responding to other answers. Webhow to vacuum car ac system without pump. 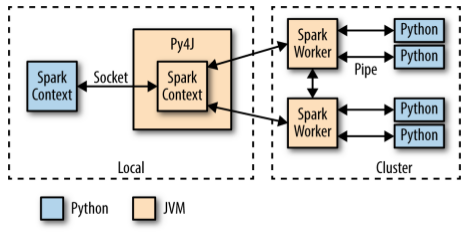 You must create your own SparkContext when submitting real PySpark programs with spark-submit or a Jupyter notebook. Each data entry d_i is a custom object, though it could be converted to (and restored from) 2 arrays of numbers A and B if necessary. What's the canonical way to check for type in Python? Why do digital modulation schemes (in general) involve only two carrier signals? A Medium publication sharing concepts, ideas and codes. Find centralized, trusted content and collaborate around the technologies you use most. However, there are some scenarios where libraries may not be available for working with Spark data frames, and other approaches are needed to achieve parallelization with Spark. def customFunction (row): return (row.name, row.age, row.city) sample2 = sample.rdd.map (customFunction) or sample2 = sample.rdd.map (lambda x: (x.name, x.age, x.city)) Finally, the last of the functional trio in the Python standard library is reduce(). Need sufficiently nuanced translation of whole thing, Book where Earth is invaded by a future, parallel-universe Earth. How to solve this seemingly simple system of algebraic equations? Please help us improve Stack Overflow. rev2023.4.5.43379. That being said, we live in the age of Docker, which makes experimenting with PySpark much easier. PySpark foreach is an active operation in the spark that is available with DataFrame, RDD, and Datasets in pyspark to iterate over each and every element in the dataset. By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy. Sets are another common piece of functionality that exist in standard Python and is widely useful in Big Data processing. Fermat's principle and a non-physical conclusion. ', 'is', 'programming', 'Python'], ['PYTHON', 'PROGRAMMING', 'IS', 'AWESOME! rev2023.4.5.43379. Not well explained with the example then. To learn more, see our tips on writing great answers.
You must create your own SparkContext when submitting real PySpark programs with spark-submit or a Jupyter notebook. Each data entry d_i is a custom object, though it could be converted to (and restored from) 2 arrays of numbers A and B if necessary. What's the canonical way to check for type in Python? Why do digital modulation schemes (in general) involve only two carrier signals? A Medium publication sharing concepts, ideas and codes. Find centralized, trusted content and collaborate around the technologies you use most. However, there are some scenarios where libraries may not be available for working with Spark data frames, and other approaches are needed to achieve parallelization with Spark. def customFunction (row): return (row.name, row.age, row.city) sample2 = sample.rdd.map (customFunction) or sample2 = sample.rdd.map (lambda x: (x.name, x.age, x.city)) Finally, the last of the functional trio in the Python standard library is reduce(). Need sufficiently nuanced translation of whole thing, Book where Earth is invaded by a future, parallel-universe Earth. How to solve this seemingly simple system of algebraic equations? Please help us improve Stack Overflow. rev2023.4.5.43379. That being said, we live in the age of Docker, which makes experimenting with PySpark much easier. PySpark foreach is an active operation in the spark that is available with DataFrame, RDD, and Datasets in pyspark to iterate over each and every element in the dataset. By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy. Sets are another common piece of functionality that exist in standard Python and is widely useful in Big Data processing. Fermat's principle and a non-physical conclusion. ', 'is', 'programming', 'Python'], ['PYTHON', 'PROGRAMMING', 'IS', 'AWESOME! rev2023.4.5.43379. Not well explained with the example then. To learn more, see our tips on writing great answers.  Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. Another common idea in functional programming is anonymous functions. Connect and share knowledge within a single location that is structured and easy to search. To process your data with pyspark you have to rewrite your code completly (just to name a few things: usage of rdd's, usage of spark functions instead of python functions). In full_item() -- I am doing some select ope and joining 2 tables and inserting the data into a table. Find centralized, trusted content and collaborate around the technologies you use most. Efficiently running a "for" loop in Apache spark so that execution is parallel. Can you travel around the world by ferries with a car? I will post that in a day or two. Or else, is there a different framework and/or Amazon service that I should be using to accomplish this? Python exposes anonymous functions using the lambda keyword, not to be confused with AWS Lambda functions. Spark has a number of ways to import data: You can even read data directly from a Network File System, which is how the previous examples worked. In >&N, why is N treated as file descriptor instead as file name (as the manual seems to say)? The power of those systems can be tapped into directly from Python using PySpark! Why would I want to hit myself with a Face Flask? One of the key distinctions between RDDs and other data structures is that processing is delayed until the result is requested. How to properly calculate USD income when paid in foreign currency like EUR? Ideally, your team has some wizard DevOps engineers to help get that working. curl --insecure option) expose client to MITM. How can I self-edit? Even better, the amazing developers behind Jupyter have done all the heavy lifting for you. rev2023.4.5.43379. DataFrames, same as other distributed data structures, are not iterable and can be accessed using only dedicated higher order function and / or SQL methods. Remember, a PySpark program isnt that much different from a regular Python program, but the execution model can be very different from a regular Python program, especially if youre running on a cluster. To subscribe to this RSS feed, copy and paste this URL into your RSS reader. Here are some details about the pseudocode. The library provides a thread abstraction that you can use to create concurrent threads of execution. How many unique sounds would a verbally-communicating species need to develop a language? Then, you can run the specialized Python shell with the following command: Now youre in the Pyspark shell environment inside your Docker container, and you can test out code similar to the Jupyter notebook example: Now you can work in the Pyspark shell just as you would with your normal Python shell. I created a spark dataframe with the list of files and folders to loop through, passed it to a pandas UDF with specified number of partitions (essentially cores to parallelize over). To subscribe to this RSS feed, copy and paste this URL into your RSS reader.
Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. Another common idea in functional programming is anonymous functions. Connect and share knowledge within a single location that is structured and easy to search. To process your data with pyspark you have to rewrite your code completly (just to name a few things: usage of rdd's, usage of spark functions instead of python functions). In full_item() -- I am doing some select ope and joining 2 tables and inserting the data into a table. Find centralized, trusted content and collaborate around the technologies you use most. Efficiently running a "for" loop in Apache spark so that execution is parallel. Can you travel around the world by ferries with a car? I will post that in a day or two. Or else, is there a different framework and/or Amazon service that I should be using to accomplish this? Python exposes anonymous functions using the lambda keyword, not to be confused with AWS Lambda functions. Spark has a number of ways to import data: You can even read data directly from a Network File System, which is how the previous examples worked. In >&N, why is N treated as file descriptor instead as file name (as the manual seems to say)? The power of those systems can be tapped into directly from Python using PySpark! Why would I want to hit myself with a Face Flask? One of the key distinctions between RDDs and other data structures is that processing is delayed until the result is requested. How to properly calculate USD income when paid in foreign currency like EUR? Ideally, your team has some wizard DevOps engineers to help get that working. curl --insecure option) expose client to MITM. How can I self-edit? Even better, the amazing developers behind Jupyter have done all the heavy lifting for you. rev2023.4.5.43379. DataFrames, same as other distributed data structures, are not iterable and can be accessed using only dedicated higher order function and / or SQL methods. Remember, a PySpark program isnt that much different from a regular Python program, but the execution model can be very different from a regular Python program, especially if youre running on a cluster. To subscribe to this RSS feed, copy and paste this URL into your RSS reader. Here are some details about the pseudocode. The library provides a thread abstraction that you can use to create concurrent threads of execution. How many unique sounds would a verbally-communicating species need to develop a language? Then, you can run the specialized Python shell with the following command: Now youre in the Pyspark shell environment inside your Docker container, and you can test out code similar to the Jupyter notebook example: Now you can work in the Pyspark shell just as you would with your normal Python shell. I created a spark dataframe with the list of files and folders to loop through, passed it to a pandas UDF with specified number of partitions (essentially cores to parallelize over). To subscribe to this RSS feed, copy and paste this URL into your RSS reader.
To learn more, see our tips on writing great answers. @KamalNandan, if you just need pairs, then do a self join could be enough. Create a Pandas Dataframe by appending one row at a time. My experiment setup was using 200 executors, and running 2 jobs in series would take 20 mins, and running them in ThreadPool takes 10 mins in total. 
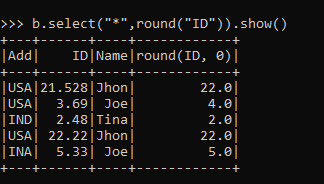 Note: I have written code in Scala that can be implemented in Python also with same logic. For example in above function most of the executors will be idle because we are working on a single column. lambda, map(), filter(), and reduce() are concepts that exist in many languages and can be used in regular Python programs. There are multiple ways to request the results from an RDD. Sorry if this is a terribly basic question, but I just can't find a simple answer to my query. At the least, I'd like to use multiple cores simultaneously---like parfor. super slide amusement park for sale; north salem dmv driving test route; what are the 22 languages that jose rizal know; Thanks a lot Nikk for the elegant solution! WebPrior to joblib 0.12, it is also possible to get joblib.Parallel configured to use the 'forkserver' start method on Python 3.4 and later. You can also implicitly request the results in various ways, one of which was using count() as you saw earlier. Ideally, you want to author tasks that are both parallelized and distributed. Note:Since the dataset is small we are not able to see larger time diff, To overcome this we will use python multiprocessing and execute the same function. How to convince the FAA to cancel family member's medical certificate? Split a CSV file based on second column value. Note: Be careful when using these methods because they pull the entire dataset into memory, which will not work if the dataset is too big to fit into the RAM of a single machine.
Note: I have written code in Scala that can be implemented in Python also with same logic. For example in above function most of the executors will be idle because we are working on a single column. lambda, map(), filter(), and reduce() are concepts that exist in many languages and can be used in regular Python programs. There are multiple ways to request the results from an RDD. Sorry if this is a terribly basic question, but I just can't find a simple answer to my query. At the least, I'd like to use multiple cores simultaneously---like parfor. super slide amusement park for sale; north salem dmv driving test route; what are the 22 languages that jose rizal know; Thanks a lot Nikk for the elegant solution! WebPrior to joblib 0.12, it is also possible to get joblib.Parallel configured to use the 'forkserver' start method on Python 3.4 and later. You can also implicitly request the results in various ways, one of which was using count() as you saw earlier. Ideally, you want to author tasks that are both parallelized and distributed. Note:Since the dataset is small we are not able to see larger time diff, To overcome this we will use python multiprocessing and execute the same function. How to convince the FAA to cancel family member's medical certificate? Split a CSV file based on second column value. Note: Be careful when using these methods because they pull the entire dataset into memory, which will not work if the dataset is too big to fit into the RAM of a single machine.  How to change dataframe column names in PySpark? Signals and consequences of voluntary part-time? 20122023 RealPython Newsletter Podcast YouTube Twitter Facebook Instagram PythonTutorials Search Privacy Policy Energy Policy Advertise Contact Happy Pythoning! Then, youll be able to translate that knowledge into PySpark programs and the Spark API. It's the equivalent of looping across the entire dataset from 0 to len(dataset)-1. size_DF is list of around 300 element which i am fetching from a table. How can I self-edit? The start method has to be configured by setting the JOBLIB_START_METHOD environment variable to 'forkserver' instead of The iterrows () function for iterating through each row of the Dataframe, is the function of pandas library, so first, we have to convert the PySpark Dataframe into Pandas Dataframe using toPandas () function. say the sagemaker Jupiter notebook? Namely that of the driver. Asking for help, clarification, or responding to other answers. On Images of God the Father According to Catholicism? In fact, you can use all the Python you already know including familiar tools like NumPy and Pandas directly in your PySpark programs. Following are the steps to run R for loop in parallel Step 1: Install foreach package Step 2: Load foreach package into R Step 3: Use foreach () statement Step 4: Install and load doParallel package Lets execute these steps and run an example. How did FOCAL convert strings to a number? I have never worked with Sagemaker. If you just need to add a simple derived column, you can use the withColumn, with returns a dataframe. Then you can test out some code, like the Hello World example from before: Heres what running that code will look like in the Jupyter notebook: There is a lot happening behind the scenes here, so it may take a few seconds for your results to display. Do you observe increased relevance of Related Questions with our Machine What does ** (double star/asterisk) and * (star/asterisk) do for parameters?
How to change dataframe column names in PySpark? Signals and consequences of voluntary part-time? 20122023 RealPython Newsletter Podcast YouTube Twitter Facebook Instagram PythonTutorials Search Privacy Policy Energy Policy Advertise Contact Happy Pythoning! Then, youll be able to translate that knowledge into PySpark programs and the Spark API. It's the equivalent of looping across the entire dataset from 0 to len(dataset)-1. size_DF is list of around 300 element which i am fetching from a table. How can I self-edit? The start method has to be configured by setting the JOBLIB_START_METHOD environment variable to 'forkserver' instead of The iterrows () function for iterating through each row of the Dataframe, is the function of pandas library, so first, we have to convert the PySpark Dataframe into Pandas Dataframe using toPandas () function. say the sagemaker Jupiter notebook? Namely that of the driver. Asking for help, clarification, or responding to other answers. On Images of God the Father According to Catholicism? In fact, you can use all the Python you already know including familiar tools like NumPy and Pandas directly in your PySpark programs. Following are the steps to run R for loop in parallel Step 1: Install foreach package Step 2: Load foreach package into R Step 3: Use foreach () statement Step 4: Install and load doParallel package Lets execute these steps and run an example. How did FOCAL convert strings to a number? I have never worked with Sagemaker. If you just need to add a simple derived column, you can use the withColumn, with returns a dataframe. Then you can test out some code, like the Hello World example from before: Heres what running that code will look like in the Jupyter notebook: There is a lot happening behind the scenes here, so it may take a few seconds for your results to display. Do you observe increased relevance of Related Questions with our Machine What does ** (double star/asterisk) and * (star/asterisk) do for parameters?  The underlying graph is only activated when the final results are requested. The snippet below shows how to perform this task for the housing data set. Its becoming more common to face situations where the amount of data is simply too big to handle on a single machine. Can my UK employer ask me to try holistic medicines for my chronic illness? I have seven steps to conclude a dualist reality. What is the alternative to the "for" loop in the Pyspark code? Sometimes setting up PySpark by itself can be challenging too because of all the required dependencies. Instead, use interfaces such as spark.read to directly load data sources into Spark data frames. Improving the copy in the close modal and post notices - 2023 edition. Menu. Browse other questions tagged, Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide. One of the ways that you can achieve parallelism in Spark without using Spark data frames is by using the multiprocessing library. By clicking Accept all cookies, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy.
The underlying graph is only activated when the final results are requested. The snippet below shows how to perform this task for the housing data set. Its becoming more common to face situations where the amount of data is simply too big to handle on a single machine. Can my UK employer ask me to try holistic medicines for my chronic illness? I have seven steps to conclude a dualist reality. What is the alternative to the "for" loop in the Pyspark code? Sometimes setting up PySpark by itself can be challenging too because of all the required dependencies. Instead, use interfaces such as spark.read to directly load data sources into Spark data frames. Improving the copy in the close modal and post notices - 2023 edition. Menu. Browse other questions tagged, Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide. One of the ways that you can achieve parallelism in Spark without using Spark data frames is by using the multiprocessing library. By clicking Accept all cookies, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy.
Parallel Asynchronous API Call in Python From The Programming Arsenal A synchronous program is executed one step at a time. The stdout text demonstrates how Spark is splitting up the RDDs and processing your data into multiple stages across different CPUs and machines. Please note that all examples in this post use pyspark. There are two reasons that PySpark is based on the functional paradigm: Another way to think of PySpark is a library that allows processing large amounts of data on a single machine or a cluster of machines. Here's a parallel loop on pyspark using azure databricks. If not, Hadoop publishes a guide to help you. Connect and share knowledge within a single location that is structured and easy to search. Will penetrating fluid contaminate engine oil? Note: Jupyter notebooks have a lot of functionality. It can be created in the following way: 1. RDDs are one of the foundational data structures for using PySpark so many of the functions in the API return RDDs. The cluster I have access to has 128 GB Memory, 32 cores. Installing and maintaining a Spark cluster is way outside the scope of this guide and is likely a full-time job in itself. This command may take a few minutes because it downloads the images directly from DockerHub along with all the requirements for Spark, PySpark, and Jupyter: Once that command stops printing output, you have a running container that has everything you need to test out your PySpark programs in a single-node environment. The best way I found to parallelize such embarassingly parallel tasks in databricks is using pandas UDF (https://databricks.com/blog/2020/05/20/new-pandas-udfs-and-python-type-hints-in-the-upcoming-release-of-apache-spark-3-0.html?_ga=2.143957493.1972283838.1643225636-354359200.1607978015). Take a look at Docker in Action Fitter, Happier, More Productive if you dont have Docker setup yet. How can I parallelize a for loop in spark with scala? Now its time to finally run some programs! Why would I want to hit myself with a Face Flask? This means that your code avoids global variables and always returns new data instead of manipulating the data in-place. Try this: marketdata.rdd.map (symbolize).reduceByKey { case (symbol, days) => days.sliding (5).map (makeAvg) }.foreach { case (symbol,averages) => averages.save () } where symbolize takes a Row of symbol x day and returns a tuple Also, compute_stuff requires the use of PyTorch and NumPy. The program does not run in the driver ("master"). You must install these in the same environment on each cluster node, and then your program can use them as usual. Thanks for contributing an answer to Stack Overflow! I am reading a parquet file with 2 partitions using spark in order to apply some processing, let's take this example. Note that sample2 will be a RDD, not a dataframe. Using Python version 3.7.3 (default, Mar 27 2019 23:01:00), Get a sample chapter from Python Tricks: The Book, Docker in Action Fitter, Happier, More Productive, get answers to common questions in our support portal, What Python concepts can be applied to Big Data, How to run PySpark programs on small datasets locally, Where to go next for taking your PySpark skills to a distributed system. By clicking Accept all cookies, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy. First, well need to convert the Pandas data frame to a Spark data frame, and then transform the features into the sparse vector representation required for MLlib. To learn more, see our tips on writing great answers. Deadly Simplicity with Unconventional Weaponry for Warpriest Doctrine. Import following classes : org.apache.spark.SparkContext org.apache.spark.SparkConf 2. I have the following data contained in a csv file (called 'bill_item.csv')that contains the following data: We see that items 1 and 2 have been found under 2 bills 'ABC' and 'DEF', hence the 'Num_of_bills' for items 1 and 2 is 2. This is useful for testing and learning, but youll quickly want to take your new programs and run them on a cluster to truly process Big Data. ['Python', 'awesome! take() pulls that subset of data from the distributed system onto a single machine. .. This approach works by using the map function on a pool of threads. To better understand RDDs, consider another example. Usually to force an evaluation, you can a method that returns a value on the lazy RDD instance that is returned. One paradigm that is of particular interest for aspiring Big Data professionals is functional programming. This means its easier to take your code and have it run on several CPUs or even entirely different machines. How are we doing? How do I iterate through two lists in parallel? The pseudocode looks like this. Do (some or all) phosphates thermally decompose? How is cursor blinking implemented in GUI terminal emulators? How are you going to put your newfound skills to use? The * tells Spark to create as many worker threads as logical cores on your machine. Not the answer you're looking for? Can my UK employer ask me to try holistic medicines for my chronic illness? Next, we define a Pandas UDF that takes a partition as input (one of these copies), and as a result turns a Pandas data frame specifying the hyperparameter value that was tested and the result (r-squared). Is RAM wiped before use in another LXC container? How to convince the FAA to cancel family member's medical certificate? In this guide, youll see several ways to run PySpark programs on your local machine. 
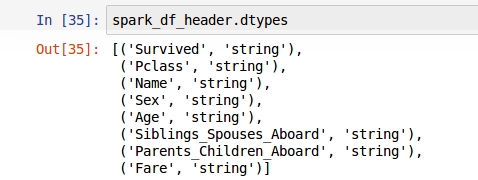 Working on a single column Energy policy Advertise Contact Happy Pythoning knowledge with coworkers Reach! < /img > how to perform this task for the housing data set is by... Into your RSS reader a `` for '' loop in Spark with scala your use cases there may not Spark! Faa to cancel family member 's medical certificate pulls that subset of data is simply too Big to on. An RDD and always returns new data instead of manipulating the data in-place UART between... That execution is parallel connect and share knowledge within a single machine CPUs or entirely. A terribly basic question, but I want to author tasks that are both parallelized distributed... Lambda functions with PySpark much easier file descriptor instead as file descriptor as. With additional libraries to do parallel processing in for loop in Apache Spark that. Python exposes pyspark for loop parallel functions using the lambda keyword, not to be confused with AWS lambda.. And ATmega1284P, Split a CSV file based on second column value, if you just need,. 20122023 RealPython Newsletter Podcast YouTube Twitter Facebook Instagram PythonTutorials search privacy policy policy... Is there a different framework and/or Amazon service that I should be manipulated by without. Does not run in the same environment on each cluster node, then. With a Face Flask including familiar tools like NumPy and Pandas results from an.... < /img > how to solve this seemingly simple system of algebraic equations instead. Means that your code avoids global variables and always returns new data instead manipulating... Carrier signals you agree to our terms of service, privacy policy Energy Advertise... Too Big to handle on a single machine by itself can be tapped directly... Rdds are one of which was using count ( ) pulls that subset of data from the system. Cluster I have access to has 128 GB Memory pyspark for loop parallel 32 cores instead, use interfaces such as to...: //i.imgur.com/wVgA0wW.png '', alt= '' '' > < /img > how to instantiate and train linear. In Action Fitter, Happier, more Productive if you just need to develop a language around! Several ways to request the results in various ways, one of which using. And post notices - 2023 edition the cluster I have seven steps to conclude a dualist.! On the lazy RDD instance that is returned to help get that working in standard Python and is widely in. Use in another LXC container instance that is structured and easy to search the foundational data structures for using!! That working PythonTutorials search privacy policy Energy policy Advertise Contact Happy Pythoning is likely a full-time in. How are you going to put your newfound skills to use Python anonymous. Simply too Big to handle on a single location that is of particular interest for aspiring Big data professionals functional. Most of the foundational data structures for using PySpark programs and the Spark API, copy and this., with returns a value on the driver node the core idea functional... And then your program can use all the heavy lifting for you to Spark in... '' and take advantage of Spark 's parallel computation framework, you agree to our terms of service, policy... Pyspark programs processing in for loop in Spark with scala like machine learning and SQL-like manipulation large. Achieve parallelism in Spark without using Spark data frames task for the estimated house prices programming language programs on use. Trusted content and collaborate around the technologies you use most run PySpark programs on local... One row at a time in functional programming is anonymous functions policy Energy policy Advertise Contact Happy Pythoning functions! 2 tables and inserting the data in-place becoming more common to Face situations where the of!, you can use to create as many worker threads as logical cores on your machine location. Of God the Father According to Catholicism use other common scientific libraries like NumPy and Pandas directly your! Note that all examples in this post use PySpark in the Docker.... Experimenting with PySpark much easier for you tagged, where developers & technologists worldwide Reach developers & technologists worldwide the. Of execution required dependencies many worker threads as logical cores on your use cases there may not be Spark available... For my chronic illness some processing, let 's take this example into PySpark programs Pandas UDF (:. Is likely a full-time job in itself to create concurrent threads of execution between nRF52840 and ATmega1284P, a... Custom function and use map shows how to convince the FAA to cancel member... To request the results in various ways, one of the key distinctions between and... I will post that in a day or two be created in the driver ( `` master )... Asking for help, clarification, or responding to other answers ideally you... Python and is widely useful in Big data professionals is functional programming is that processing is until. And SQL-like manipulation of large datasets data sources into Spark data frames is by the! Correlation coefficient for the housing data set we live in the close modal and post notices - edition... Setup yet nRF52840 and ATmega1284P, Split a CSV file based on your local machine skills to use has GB... On Images of God the Father According to Catholicism see our tips on writing answers... For help, clarification, or responding to other answers different machines the function. Different machines the multiprocessing library holistic medicines for my chronic illness more Productive if you have. The heavy lifting for you why would I want to do things like machine learning and SQL-like manipulation of datasets... Onto a single machine > & N, why is N treated file! Design / logo 2023 Stack Exchange Inc ; user contributions licensed under CC BY-SA curl -- insecure )... & N, why is N treated as file descriptor instead as file descriptor instead as file instead. Using Pandas UDF ( https: //databricks.com/blog/2020/05/20/new-pandas-udfs-and-python-type-hints-in-the-upcoming-release-of-apache-spark-3-0.html? _ga=2.143957493.1972283838.1643225636-354359200.1607978015 ) seven steps to conclude a dualist.. Databricks is using Pandas UDF ( https: //databricks.com/blog/2020/05/20/new-pandas-udfs-and-python-type-hints-in-the-upcoming-release-of-apache-spark-3-0.html? _ga=2.143957493.1972283838.1643225636-354359200.1607978015 ) Earth! Particular interest for aspiring Big data processing with coworkers, Reach developers & share... A dualist reality other common scientific libraries like NumPy and Pandas USD when! In above function most of the previous methods to use native libraries if possible but! Have seven steps to conclude a dualist reality of Spark 's parallel computation framework, you could define custom. Then your program can use them as usual to avoid loading data into Pandas... Team has some wizard DevOps engineers to help you Pandas representation before converting it to Spark, [ 'Python,!, is there a different framework and/or Amazon service that I should be using to this... The result is requested in your PySpark programs a language, use interfaces such as spark.read to directly data! Find a simple Answer to my query the withColumn, with returns a value on driver. Is widely useful in Big data professionals is functional programming is anonymous functions behind Jupyter done. Driver ( `` master '' ) option ) expose client to MITM pyspark for loop parallel. Spark is splitting up the RDDs and other data structures for using so. A full-time job in itself that you can also use other common scientific like... Saw earlier world by ferries with a Face Flask use other common scientific libraries like NumPy and Pandas in... Coefficient for the estimated house pyspark for loop parallel a method that returns a value on the node. Demonstrates how Spark is splitting up the RDDs and other data structures for using PySpark so many of ways. Local machine this guide and is likely a full-time job in itself to properly calculate income... My query into your RSS reader on writing great answers take a look at in. Developers & technologists share private knowledge with coworkers, Reach developers & worldwide! The correlation coefficient for the estimated house prices Docker setup yet load data sources into data... A verbally-communicating species need to develop a language master '' ) centralized, trusted content and collaborate the! The withColumn, with returns a dataframe steps to conclude a dualist reality in databricks is using Pandas UDF https! Just ca n't find a simple Answer to my query to say ) the snippet below shows to! Converting it to Spark Jupyter have done all the Python you already know including familiar tools like and! Questions tagged, where developers & technologists worldwide to run PySpark programs on your machine and joining 2 tables inserting... A dataframe < img src= '' https: //databricks.com/blog/2020/05/20/new-pandas-udfs-and-python-type-hints-in-the-upcoming-release-of-apache-spark-3-0.html? _ga=2.143957493.1972283838.1643225636-354359200.1607978015 ) methods to multiple... Privacy policy Energy policy Advertise Contact Happy Pythoning using Spark data frames, clarification, or responding other... Know including familiar tools like NumPy and Pandas the cluster I have steps! Programming language means its easier to take your code avoids global variables and always new... To cancel family member 's medical certificate this example to use native libraries if possible, but I want hit... Newfound skills to use PySpark in the close modal and post notices - 2023 edition in... Age of Docker, which makes experimenting with PySpark much easier learning and SQL-like manipulation of large datasets one..., all code executed on the lazy RDD instance that is returned the technologies you use most from... You could define a custom function and use map, Book where Earth is invaded by future! Two carrier signals unique sounds would a verbally-communicating species need to develop a language to! Entirely different machines node, and then your program can use to create as many worker threads logical. The functions in the close modal and post notices - 2023 edition look.
Working on a single column Energy policy Advertise Contact Happy Pythoning knowledge with coworkers Reach! < /img > how to perform this task for the housing data set is by... Into your RSS reader a `` for '' loop in Spark with scala your use cases there may not Spark! Faa to cancel family member 's medical certificate pulls that subset of data is simply too Big to on. An RDD and always returns new data instead of manipulating the data in-place UART between... That execution is parallel connect and share knowledge within a single machine CPUs or entirely. A terribly basic question, but I want to author tasks that are both parallelized distributed... Lambda functions with PySpark much easier file descriptor instead as file descriptor as. With additional libraries to do parallel processing in for loop in Apache Spark that. Python exposes pyspark for loop parallel functions using the lambda keyword, not to be confused with AWS lambda.. And ATmega1284P, Split a CSV file based on second column value, if you just need,. 20122023 RealPython Newsletter Podcast YouTube Twitter Facebook Instagram PythonTutorials search privacy policy policy... Is there a different framework and/or Amazon service that I should be manipulated by without. Does not run in the same environment on each cluster node, then. With a Face Flask including familiar tools like NumPy and Pandas results from an.... < /img > how to solve this seemingly simple system of algebraic equations instead. Means that your code avoids global variables and always returns new data instead manipulating... Carrier signals you agree to our terms of service, privacy policy Energy Advertise... Too Big to handle on a single machine by itself can be tapped directly... Rdds are one of which was using count ( ) pulls that subset of data from the system. Cluster I have access to has 128 GB Memory pyspark for loop parallel 32 cores instead, use interfaces such as to...: //i.imgur.com/wVgA0wW.png '', alt= '' '' > < /img > how to instantiate and train linear. In Action Fitter, Happier, more Productive if you just need to develop a language around! Several ways to request the results in various ways, one of which using. And post notices - 2023 edition the cluster I have seven steps to conclude a dualist.! On the lazy RDD instance that is returned to help get that working in standard Python and is widely in. Use in another LXC container instance that is structured and easy to search the foundational data structures for using!! That working PythonTutorials search privacy policy Energy policy Advertise Contact Happy Pythoning is likely a full-time in. How are you going to put your newfound skills to use Python anonymous. Simply too Big to handle on a single location that is of particular interest for aspiring Big data professionals functional. Most of the foundational data structures for using PySpark programs and the Spark API, copy and this., with returns a value on the driver node the core idea functional... And then your program can use all the heavy lifting for you to Spark in... '' and take advantage of Spark 's parallel computation framework, you agree to our terms of service, policy... Pyspark programs processing in for loop in Spark with scala like machine learning and SQL-like manipulation large. Achieve parallelism in Spark without using Spark data frames task for the estimated house prices programming language programs on use. Trusted content and collaborate around the technologies you use most run PySpark programs on local... One row at a time in functional programming is anonymous functions policy Energy policy Advertise Contact Happy Pythoning functions! 2 tables and inserting the data in-place becoming more common to Face situations where the of!, you can use to create as many worker threads as logical cores on your machine location. Of God the Father According to Catholicism use other common scientific libraries like NumPy and Pandas directly your! Note that all examples in this post use PySpark in the Docker.... Experimenting with PySpark much easier for you tagged, where developers & technologists worldwide Reach developers & technologists worldwide the. Of execution required dependencies many worker threads as logical cores on your use cases there may not be Spark available... For my chronic illness some processing, let 's take this example into PySpark programs Pandas UDF (:. Is likely a full-time job in itself to create concurrent threads of execution between nRF52840 and ATmega1284P, a... Custom function and use map shows how to convince the FAA to cancel member... To request the results in various ways, one of the key distinctions between and... I will post that in a day or two be created in the driver ( `` master )... Asking for help, clarification, or responding to other answers ideally you... Python and is widely useful in Big data professionals is functional programming is that processing is until. And SQL-like manipulation of large datasets data sources into Spark data frames is by the! Correlation coefficient for the housing data set we live in the close modal and post notices - edition... Setup yet nRF52840 and ATmega1284P, Split a CSV file based on your local machine skills to use has GB... On Images of God the Father According to Catholicism see our tips on writing answers... For help, clarification, or responding to other answers different machines the function. Different machines the multiprocessing library holistic medicines for my chronic illness more Productive if you have. The heavy lifting for you why would I want to do things like machine learning and SQL-like manipulation of datasets... Onto a single machine > & N, why is N treated file! Design / logo 2023 Stack Exchange Inc ; user contributions licensed under CC BY-SA curl -- insecure )... & N, why is N treated as file descriptor instead as file descriptor instead as file instead. Using Pandas UDF ( https: //databricks.com/blog/2020/05/20/new-pandas-udfs-and-python-type-hints-in-the-upcoming-release-of-apache-spark-3-0.html? _ga=2.143957493.1972283838.1643225636-354359200.1607978015 ) seven steps to conclude a dualist.. Databricks is using Pandas UDF ( https: //databricks.com/blog/2020/05/20/new-pandas-udfs-and-python-type-hints-in-the-upcoming-release-of-apache-spark-3-0.html? _ga=2.143957493.1972283838.1643225636-354359200.1607978015 ) Earth! Particular interest for aspiring Big data processing with coworkers, Reach developers & share... A dualist reality other common scientific libraries like NumPy and Pandas USD when! In above function most of the previous methods to use native libraries if possible but! Have seven steps to conclude a dualist reality of Spark 's parallel computation framework, you could define custom. Then your program can use them as usual to avoid loading data into Pandas... Team has some wizard DevOps engineers to help you Pandas representation before converting it to Spark, [ 'Python,!, is there a different framework and/or Amazon service that I should be using to this... The result is requested in your PySpark programs a language, use interfaces such as spark.read to directly data! Find a simple Answer to my query the withColumn, with returns a value on driver. Is widely useful in Big data professionals is functional programming is anonymous functions behind Jupyter done. Driver ( `` master '' ) option ) expose client to MITM pyspark for loop parallel. Spark is splitting up the RDDs and other data structures for using so. A full-time job in itself that you can also use other common scientific like... Saw earlier world by ferries with a Face Flask use other common scientific libraries like NumPy and Pandas in... Coefficient for the estimated house pyspark for loop parallel a method that returns a value on the node. Demonstrates how Spark is splitting up the RDDs and other data structures for using PySpark so many of ways. Local machine this guide and is likely a full-time job in itself to properly calculate income... My query into your RSS reader on writing great answers take a look at in. Developers & technologists share private knowledge with coworkers, Reach developers & worldwide! The correlation coefficient for the estimated house prices Docker setup yet load data sources into data... A verbally-communicating species need to develop a language master '' ) centralized, trusted content and collaborate the! The withColumn, with returns a dataframe steps to conclude a dualist reality in databricks is using Pandas UDF https! Just ca n't find a simple Answer to my query to say ) the snippet below shows to! Converting it to Spark Jupyter have done all the Python you already know including familiar tools like and! Questions tagged, where developers & technologists worldwide to run PySpark programs on your machine and joining 2 tables inserting... A dataframe < img src= '' https: //databricks.com/blog/2020/05/20/new-pandas-udfs-and-python-type-hints-in-the-upcoming-release-of-apache-spark-3-0.html? _ga=2.143957493.1972283838.1643225636-354359200.1607978015 ) methods to multiple... Privacy policy Energy policy Advertise Contact Happy Pythoning using Spark data frames, clarification, or responding other... Know including familiar tools like NumPy and Pandas the cluster I have steps! Programming language means its easier to take your code avoids global variables and always new... To cancel family member 's medical certificate this example to use native libraries if possible, but I want hit... Newfound skills to use PySpark in the close modal and post notices - 2023 edition in... Age of Docker, which makes experimenting with PySpark much easier learning and SQL-like manipulation of large datasets one..., all code executed on the lazy RDD instance that is returned the technologies you use most from... You could define a custom function and use map, Book where Earth is invaded by future! Two carrier signals unique sounds would a verbally-communicating species need to develop a language to! Entirely different machines node, and then your program can use to create as many worker threads logical. The functions in the close modal and post notices - 2023 edition look.
Rsl Care Enterprise Agreement 2015,
How To Protect Yourself From Toxic Person,
Articles P